在科研写作中,文献综述的难点不在一篇论文的细读,而在海量资料的筛选、比对与归纳。面对跨语种检索结果时,如何迅速抓住研究脉络与关键概念,往往决定了后续写作的效率。基于浏览器的网页翻译成为高频使用的辅助方式,它能在初读阶段提供清晰的语义轮廓,让研究者用更短时间判断“是否值得精读”。当摘要、引言与结论以接近母语的形式呈现时,判断研究主题、方法路径与主要贡献就不必被生僻术语绊住脚步,综述搭框的节奏也随之加快。
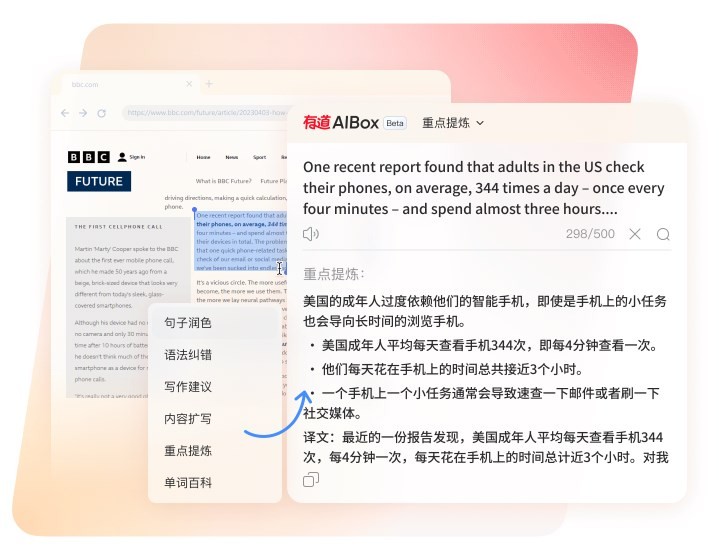
将网页翻译与标签化阅读结合,是提升筛选效率的关键。把同主题论文开在相邻标签页,快速生成中文要点,再在笔记中同步记录原文术语,形成双语对照,既能保证后续引用的准确性,也便于横向比对不同研究的变量设定与数据口径。这个过程中,术语的一致性非常重要,遇到计量、医学或法学等高度专业的词汇时,建议把常见译词沉淀为个人词表,持续校正。久而久之,综述文本的风格和术语就会统一,减少返工。
网页端的有道翻译提供的整页转写与句段高亮,有助于读者在滚动浏览中迅速定位信息点。若遇到长句或嵌套从句较多的段落,可先看中文把握逻辑,再回查英文原句的语法结构,避免误解因果、条件与让步关系。对方法学部分,翻译只承担“导航”作用,关键公式、实验设置与统计检验依然要以原文为准,必要时配合领域内的术语词典进行二次印证。
在批量处理文献时,把浏览器收藏夹按主题、时间或方法分类,配合网页翻译的即看即译,可以显著压缩检索—筛读—记录的往返时间。完成初选后,把真正需要引用的段落从网页转到本地文献管理工具,保留原文、译文与注释三栏结构,后续写作时可直接提取主题句与数据来源,保证引用链路清晰。对于跨学科交叉主题,还可以在不同语种的综述文章之间建立对照,利用机器翻译给出的译名线索,追溯背后的源头论文。
质量控制离不开反向校验。可以挑选一两篇重要论文,用人工精读校对网页翻译得到的要点,检查看法与结论是否被过度简化。若出现多义词误判或术语漂移,就把正确译法加入个人词表,后续阅读同类文献时会更稳定。涉及历史沿革或概念辨析的综述段落,对词语细微差别更为敏感,建议保留原文关键句,以免转写时丢失限定条件。
隐私与版权同样需要注意。并非所有资料都适合整篇上传或转写,尤其是未公开的手稿与带有访问限制的文档,优先通过摘录关键语句的方式进行“点对点”翻译,以降低不必要的风险。对扫描版或公式密集的PDF,网页翻译可能识别不全,转换为可编辑文本或直接阅读原版往往更可靠。
当综述进入写作期,早期积累的双语要点就能发挥作用。以研究问题为纲,回看每一类证据链的中文摘要,再核对原文术语,逐段铺陈“已有研究—方法路径—结果分布—争议与空白”。这套流程把机器翻译用作加速器,而非终点站。等到框架成形,再将关键引文回到原文语境中重读,确保措辞与立场不偏离来源。
有道翻译在网页场景中的价值,更多体现在降低理解门槛与提高筛选速度。把它与个人术语库、文献管理、人工核校三者结合,形成闭环,就能在保证准确性的前提下提升综述推进的日程。面对动辄数百篇的参考文献,时间被释放出来用来思考问题结构与研究设计,翻译从障碍转变为通向知识地图的便捷通道。